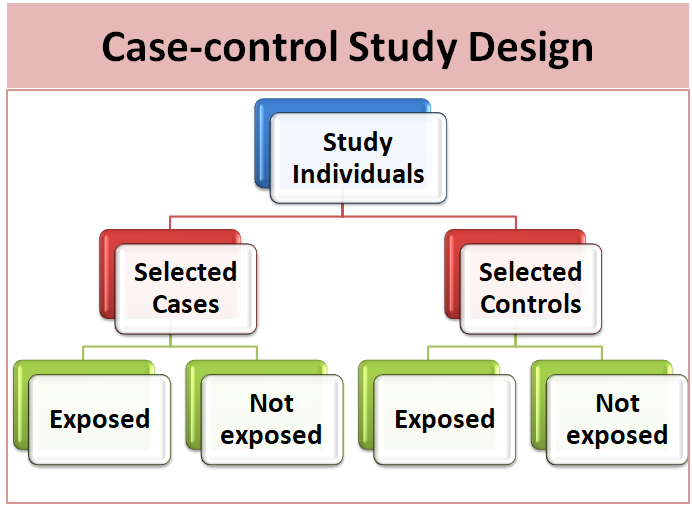






The case-control study is an analytic epidemiological research design in which the study population consists of two groups i.e. case (subjects who have a particular health problem or outcome) and controls (subjects who do not have a particular health problem or outcome). A primary use of case-control studies is to assess risk and study causes. Investigator looks back in time to determine the exposure of study subjects. This exposure is then compared between these two study subjects (cases and controls) to measure whether the exposure could account for a health condition. We cannot determine the incidence rate from a case-control study.
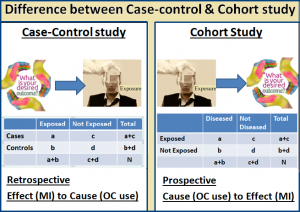 Selection of cases and controls plays a very important role in the case-control design and it is often a controversial component of the case-control design. There are many challenges selecting case and controls like matching. The criteria used to select controls should be comparable in all ways with the criteria used to select cases except disease status. The purpose of matching case-controls is to adjust effects of relevant co-factors. It is a design and accounted in the analysis. An optimal matching scheme involves only a few variables which improve statistical efficiency or eliminate bias from the effect of interest. It is always best to match basic descriptors like age, sex, race etc. Overzealous matching may have adverse effects like underestimate of odds ration and lead to false sense of security.
Selection of cases and controls plays a very important role in the case-control design and it is often a controversial component of the case-control design. There are many challenges selecting case and controls like matching. The criteria used to select controls should be comparable in all ways with the criteria used to select cases except disease status. The purpose of matching case-controls is to adjust effects of relevant co-factors. It is a design and accounted in the analysis. An optimal matching scheme involves only a few variables which improve statistical efficiency or eliminate bias from the effect of interest. It is always best to match basic descriptors like age, sex, race etc. Overzealous matching may have adverse effects like underestimate of odds ration and lead to false sense of security.
Matched control groups are useful if potential confounders are difficult to measure or if there are many different groups (e.g., professions). For matched case-control studies, it is necessary to analyze these data using stratified analysis like Mantel-Haenszel estimates or conditional logistic regression as exposure distribution in controls can differ from the exposure in the population.
For example, smoking is a risk factor for thrombosis, and partners often may have similar smoking habits. Therefore, the prevalence of smoking in the matched control group is higher than that in the unmatched control group, yielding biased odds ratios if matching is ignored. Hence, it is incorrect to pool data from several control groups together in one large data set and analyzes these data with unconditional logistic regression.
Association between exposure and outcome is the mixture of a true estimate, bias, random error and confounding effect. In a real world, you cannot measure the true estimate of association. Bias refers to an error in the design or conduct of a study that results in a conclusion which is different from the truth. It may affect internal as well as external validity. Random error is sampling error while confounding is the situation where an association between exposure and outcome is entirely or partially due to another exposure (confounder).
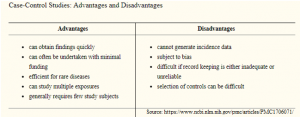 Being retrospective in nature, case-control studies are sometimes less valued. However, they are efficient enough identifying an association between exposure and outcome. Sporadically they are the only ethical way to investigate an association. If care is taken with an explanation, controls selection and potential bias reduction, case-control studies can generate valuable information.
Being retrospective in nature, case-control studies are sometimes less valued. However, they are efficient enough identifying an association between exposure and outcome. Sporadically they are the only ethical way to investigate an association. If care is taken with an explanation, controls selection and potential bias reduction, case-control studies can generate valuable information.
Last modified: 21/11/2019